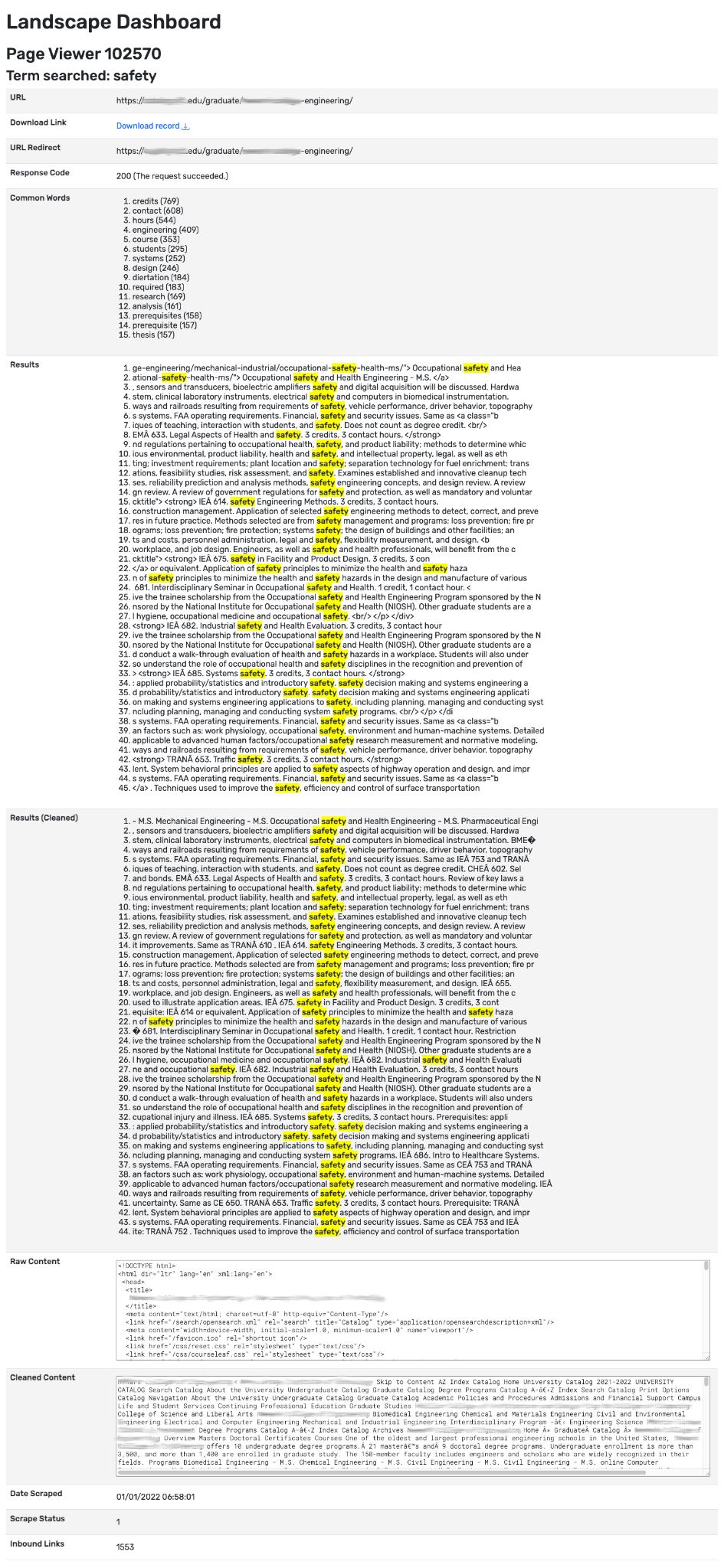
The Webscraper
Web scraping entails accessing content published on a website with tools that automate the browsing process, enabling large numbers of pages to be scraped consistently, comprehensively, and relatively quickly. Web scrapers retrieve and catalog content, storing many pages in a well-structured repository that can later be searched, browsed, or otherwise reviewed.
In creating a custom web scraper, the NEP enabled large datasets to be assembled and queried to explore, efficiently and accurately, questions central to our mission:
- Where, how, and how often do institutions communicate about ethics?
- How does ethics-related communication compare to language typically found in mission, vision, and value statements, for example, “innovation,” “excellence,” or “diversity”?
- Is ethics central or incidental messaging?
Webscraper Features
Some variables were calculated automatically once data was collected via the scrapping process, including the following:
- The relative prominence of different keywords. For a given institution, how often does one keyword and all its derivations (e.g., “ethics”) compare to another keyword and all its derivations (e.g., “moral”)?
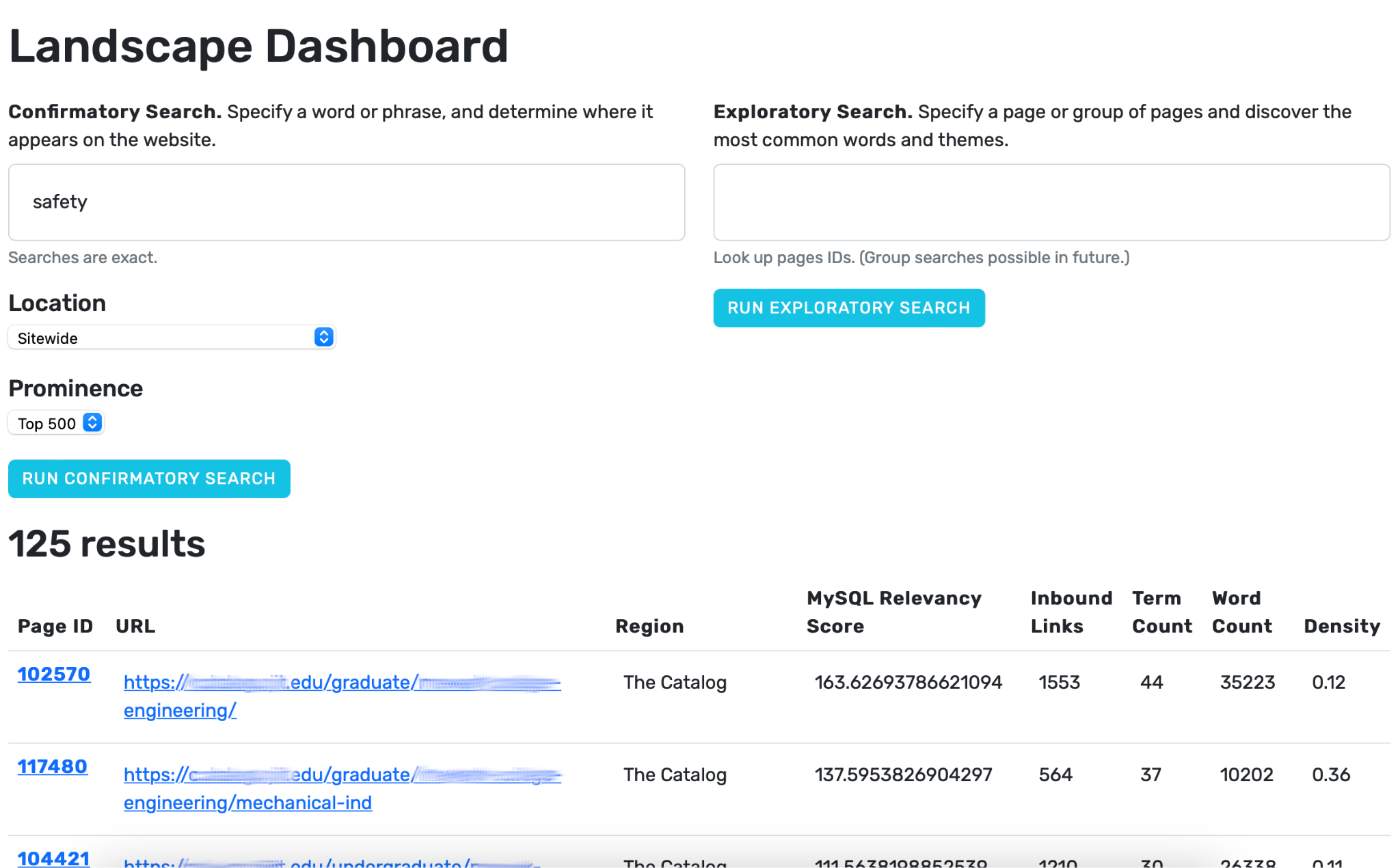
- The relative prominence of different derivations of words (e.g., how often does "ethics" appear compared to "ethically").
- The prominence of a page about ethics education within the institution's presence, based on the number of inbound links.